javascript-algorithms
Algorithmes et Structures de Données en JavaScript
![]()
![]()
Ce dépôt contient des exemples d’implémentation en JavaScript de plusieurs algorithmes et structures de données populaires.
Chaque algorithme et structure de donnée possède son propre README contenant les explications détaillées et liens (incluant aussi des vidéos Youtube) pour complément d’informations.
Lisez ceci dans d’autres langues: English, 简体中文, 繁體中文, 한국어, 日本語, Polski, Español, Português, Русский, Türk, Italiana
Data Structures
Une structure de données est une manière spéciale d’organiser et de stocker des données dans un ordinateur de manière à ce que l’on puisse accéder à cette information et la modifier de manière efficiente. De manière plus spécifique, une structure de données est un ensemble composé d’une collection de valeurs, des relations entre ces valeurs ainsi que d’un ensemble de fonctions ou d’opérations pouvant être appliquées sur ces données.
B - Débutant, A - Avancé
BListe ChaînéeBListe Doublement ChaînéeBQueueBPileBTable de HachageBTasBQueue de PrioritéATrieAArbreAArbre de recherche BinaireAArbre AVLAArbre Red-BlackAArbre de Segments - avec exemples de requêtes de type min/max/somme sur intervallesAArbre de Fenwick (Arbre Binaire Indexé)
AGraphe (orienté et non orienté)AEnsembles DisjointsAFiltre de Bloom
Algorithmes
Un algorithme est une démarche non ambigüe expliquant comment résoudre une classe de problèmes. C’est un ensemble de règles décrivant de manière précise une séquence d’opérations.
B - Débutant, A - Avancé
Algorithmes par topic
- Math
BManipulation de Bit - définir/obtenir/mettre à jour/effacer les bits, multiplication/division par deux, négativiser etc.BFactorielleBNombre de FibonacciBTest de Primalité (méthode du test de division)BAlgorithme d’Euclide - calcule le Plus Grand Commun Diviseur (PGCD)BPlus Petit Commun Multiple (PPCM)BCrible d’Eratosthène - trouve tous les nombres premiers inférieurs à une certaine limiteBPuissance de Deux - teste si un nombre donné est une puissance de deux (algorithmes naif et basé sur les opérations bit-à-bit)BTriangle de PascalBNombre complexe - nombres complexes et opérations de basesAPartition EntièreAApproximation de π par l’algorithme de Liu Hui - approximation du calcul de π basé sur les N-gonsBExponentiation rapideATransformée de Fourier Discrète - décomposer une fonction du temps (un signal) en fréquences qui la composent
- Ensembles
BProduit Cartésien - produit de plusieurs ensemblesBMélange de Fisher–Yates - permulation aléatoire d’une séquence finieAEnsemble des parties d’un ensemble - tous les sous-ensembles d’un ensembleAPermutations (avec et sans répétitions)ACombinaisons (avec et sans répétitions)APlus Longue Sous-séquence CommuneAPlus Longue Sous-suite strictement croissanteAPlus Courte Super-séquence CommuneAProblème du Sac à Dos - versions “0/1” et “Sans Contraintes”ASous-partie Maximum - versions “Force Brute” et “Programmation Dynamique” (Kadane)ASomme combinatoire - trouve toutes les combinaisons qui forment une somme spécifique
- Chaînes de Caractères
BDistance de Hamming - nombre de positions auxquelles les symboles sont différentsADistance de Levenshtein - distance minimale d’édition entre deux séquencesAAlgorithme de Knuth–Morris–Pratt (Algorithme KMP) - recherche de sous-chaîne (pattern matching)AAlgorithme Z - recherche de sous-chaîne (pattern matching)AAlgorithme de Rabin Karp - recherche de sous-chaîneAPlus Longue Sous-chaîne CommuneAExpression Régulière
- Recherche
BRecherche LinéaireBJump Search Recherche par saut (ou par bloc) - recherche dans une liste triéeBRecherche Binaire - recherche dans une liste triéeBRecherche par Interpolation - recherche dans une liste triée et uniformément distribuée
- Tri
BTri BulletBTri SélectionBTri InsertionBTri Par TasBTri FusionBTri Rapide - implémentations in-place et non in-placeBTri ShellBTri ComptageBTri Radix
- Arbres
BParcours en Profondeur (DFS)BParcours en Largeur (BFS)
- Graphes
BParcours en Profondeur (DFS)BParcours en Largeur (BFS)BAlgorithme de Kruskal - trouver l’arbre couvrant de poids minimal sur un graphe pondéré non dirigéAAlgorithme de Dijkstra - trouver tous les plus courts chemins partant d’un noeud vers tous les autres noeuds dans un grapheAAlgorithme de Bellman-Ford - trouver tous les plus courts chemins partant d’un noeud vers tous les autres noeuds dans un grapheAAlgorithme de Floyd-Warshall - trouver tous les plus courts chemins entre toutes les paires de noeuds dans un grapheADétection de Cycle - pour les graphes dirigés et non dirigés (implémentations basées sur l’algorithme de Parcours en Profondeur et sur les Ensembles Disjoints)AAlgorithme de Prim - trouver l’arbre couvrant de poids minimal sur un graphe pondéré non dirigéATri Topologique - méthode DFSAPoint d’Articulation - algorithme de Tarjan (basé sur l’algorithme de Parcours en Profondeur)ABridges - algorithme basé sur le Parcours en ProfondeurAChemin Eulérien et Circuit Eulérien - algorithme de Fleury - visite chaque arc exactement une foisACycle Hamiltonien - visite chaque noeud exactement une foisAComposants Fortements Connexes - algorithme de KosarajuAProblème du Voyageur de Commerce - chemin le plus court visitant chaque cité et retournant à la cité d’origine
- Non catégorisé
BTours de HanoiBRotation de Matrice Carrée - algorithme in placeBJump Game - retour sur trace, programmation dynamique (haut-bas + bas-haut) et exemples gourmandsBChemins Uniques - retour sur trace, programmation dynamique (haut-bas + bas-haut) et exemples basés sur le Triangle de PascalAProblème des N-DamesAProblème du Cavalier
Algorithmes par Paradigme
Un paradigme algorithmique est une méthode générique ou une approche qui sous-tend la conception d’une classe d’algorithmes. C’est une abstraction au-dessus de la notion d’algorithme, tout comme l’algorithme est une abstraction supérieure à un programme informatique.
- Force Brute - cherche parmi toutes les possibilités et retient la meilleure
BRecherche LinéaireASous-partie MaximumAProblème du Voyageur de Commerce - chemin le plus court visitant chaque cité et retournant à la cité d’origine
- Gourmand - choisit la meilleure option à l’instant courant, sans tenir compte de la situation future
BJump GameAProblème du Sac à Dos Sans ContraintesAAlgorithme de Dijkstra - trouver tous les plus courts chemins partant d’un noeud vers tous les autres noeuds dans un grapheAAlgorithme de Prim - trouver l’arbre couvrant de poids minimal sur un graphe pondéré non dirigéAAlgorithme de Kruskal - trouver l’arbre couvrant de poids minimal sur un graphe pondéré non dirigé
- Diviser et Régner - divise le problème en sous problèmes (plus simples) et résoud ces sous problèmes
BRecherche BinaireBTours de HanoiBTriangle de PascalBAlgorithme d’Euclide - calcule le Plus Grand Commun Diviseur (PGCD)BTri FusionBTri RapideBArbre de Parcours en Profondeur (DFS)BGraphe de Parcours en Profondeur (DFS)BJump GameAPermutations (avec et sans répétitions)ACombinations (avec et sans répétitions)
- Programmation Dynamique - construit une solution en utilisant les solutions précédemment trouvées
BNombre de FibonacciBJump GameBChemins UniquesADistance de Levenshtein - distance minimale d’édition entre deux séquencesAPlus Longue Sous-séquence CommuneAPlus Longue Sous-chaîne CommuneAPlus Longue Sous-suite strictement croissanteAPlus Courte Super-séquence CommuneAProblème de Sac à DosAPartition EntièreASous-partie MaximumAAlgorithme de Bellman-Ford - trouver tous les plus courts chemins partant d’un noeud vers tous les autres noeuds dans un grapheAAlgorithme de Floyd-Warshall - trouver tous les plus courts chemins entre toutes les paires de noeuds dans un grapheAExpression Régulière
- Retour sur trace - de même que la version “Force Brute”, essaie de générer toutes les solutions possibles, mais pour chaque solution générée, on teste si elle satisfait toutes les conditions, et seulement ensuite continuer à générer des solutions ultérieures. Sinon, l’on revient en arrière, et l’on essaie un
chemin différent pour tester d’autres solutions. Normalement, la traversée en profondeur de l’espace d’états est utilisée.
BJump GameBUnique PathsAHamiltonian Cycle - Visit every vertex exactly onceAProblème des N-DamesAProblème du CavalierASomme combinatoire - trouve toutes les combinaisons qui forment une somme spécifique
- Séparation et Evaluation - pemet de retenir une solution à moindre coût dans un ensemble. Pour chaque étape, l’on garde une trace de la solution la moins coûteuse trouvée jusqu’à présent en tant que borne inférieure du coût. Cela afin d’éliminer les solutions partielles dont les coûts sont plus élevés que celui de la solution actuelle retenue. Normalement, la traversée en largeur en combinaison avec la traversée en profondeur de l’espace d’états de l’arbre est utilisée.
Comment utiliser ce dépôt
Installer toutes les dépendances
npm install
Exécuter ESLint
Vous pouvez l’installer pour tester la qualité du code.
npm run lint
Exécuter tous les tests
npm test
Exécuter les tests par nom
npm test -- 'LinkedList'
Tests personnalisés
Vous pouvez manipuler les structures de données et algorithmes présents dans ce
dépôt avec le fichier ./src/playground/playground.js et écrire vos propres
tests dans file ./src/playground/__test__/playground.test.js.
Vous pourrez alors simplement exécuter la commande suivante afin de tester si votre code fonctionne comme escompté
npm test -- 'playground'
Informations Utiles
Références
▶ Structures de Données et Algorithmes sur YouTube
Notation Grand O
Comparaison de la performance d’algorithmes en notation Grand O.
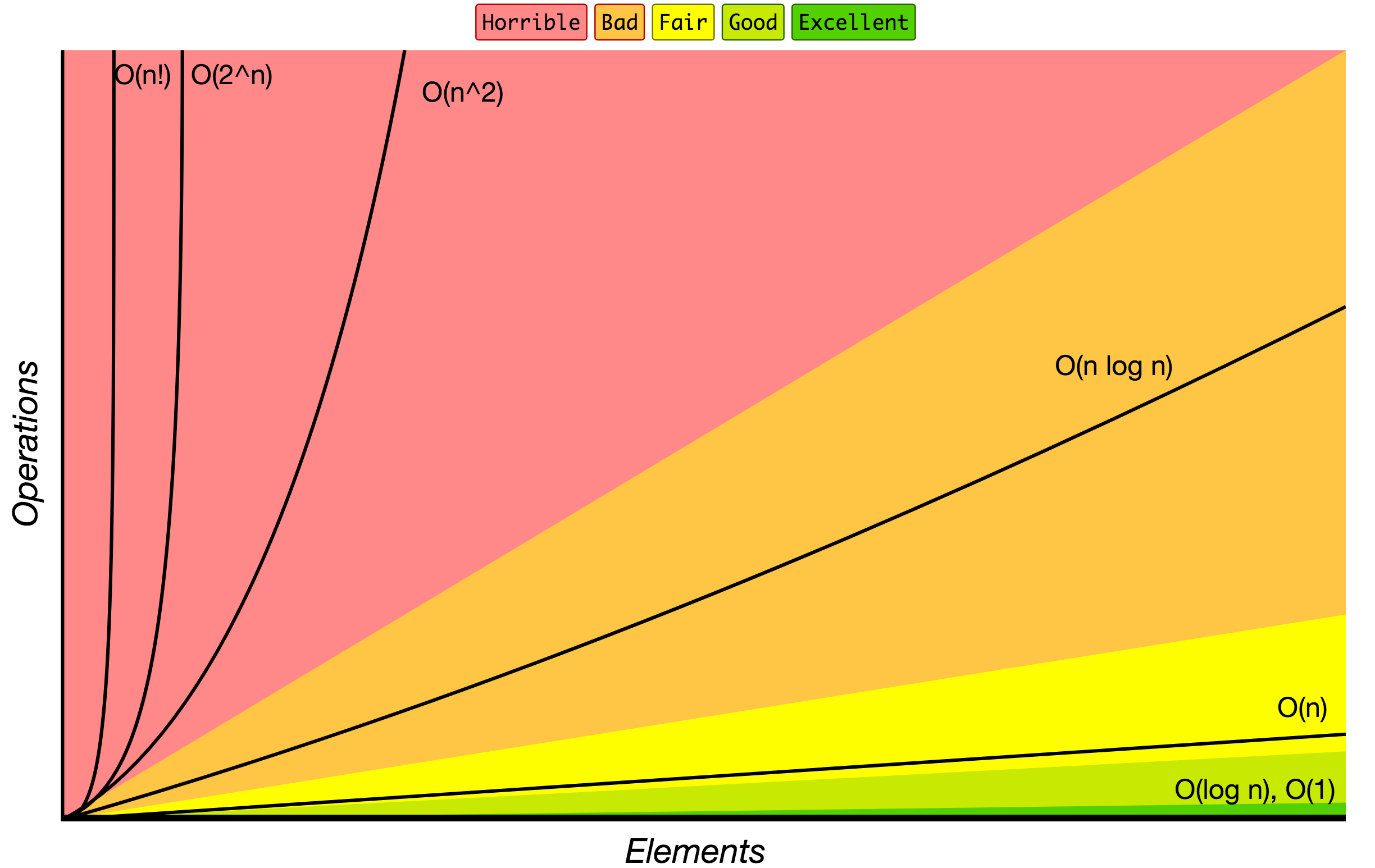
Source: Big O Cheat Sheet.
Voici la liste de certaines des notations Grand O les plus utilisées et de leurs comparaisons de performance suivant différentes tailles pour les données d’entrée.
| Notation Grand O | Opérations pour 10 éléments | Opérations pour 100 éléments | Opérations pour 1000 éléments |
|---|---|---|---|
| O(1) | 1 | 1 | 1 |
| O(log N) | 3 | 6 | 9 |
| O(N) | 10 | 100 | 1000 |
| O(N log N) | 30 | 600 | 9000 |
| O(N^2) | 100 | 10000 | 1000000 |
| O(2^N) | 1024 | 1.26e+29 | 1.07e+301 |
| O(N!) | 3628800 | 9.3e+157 | 4.02e+2567 |
Complexité des Opérations suivant les Structures de Données
| Structure de donnée | Accès | Recherche | Insertion | Suppression | Commentaires |
|---|---|---|---|---|---|
| Liste | 1 | n | n | n | |
| Pile | n | n | 1 | 1 | |
| Queue | n | n | 1 | 1 | |
| Liste Liée | n | n | 1 | 1 | |
| Table de Hachage | - | n | n | n | Dans le cas des fonctions de hachage parfaites, les couts seraient de O(1) |
| Arbre de Recherche Binaire | n | n | n | n | Dans le cas des arbre équilibrés, les coûts seraient de O(log(n)) |
| Arbre B | log(n) | log(n) | log(n) | log(n) | |
| Arbre Red-Black | log(n) | log(n) | log(n) | log(n) | |
| Arbre AVL | log(n) | log(n) | log(n) | log(n) | |
| Filtre de Bloom | - | 1 | 1 | - | Les faux positifs sont possibles lors de la recherche |
Complexité des Algorithmes de Tri de Liste
| Nom | Meilleur | Moyenne | Pire | Mémoire | Stable | Commentaires |
|---|---|---|---|---|---|---|
| Tri Bulle | n | n2 | n2 | 1 | Oui | |
| Tri Insertion | n | n2 | n2 | 1 | Oui | |
| Tri Sélection | n2 | n2 | n2 | 1 | Non | |
| Tri par Tas | n log(n) | n log(n) | n log(n) | 1 | Non | |
| Merge sort | n log(n) | n log(n) | n log(n) | n | Oui | |
| Tri Rapide | n log(n) | n log(n) | n2 | log(n) | Non | le Tri Rapide est généralement effectué in-place avec une pile de taille O(log(n)) |
| Tri Shell | n log(n) | dépend du gap séquence | n (log(n))2 | 1 | Non | |
| Tri Comptage | n + r | n + r | n + r | n + r | Oui | r - le plus grand nombre dans la liste |
| Tri Radix | n * k | n * k | n * k | n + k | Non | k - longueur du plus long index |