javascript-algorithms
Estrutura de Dados e Algoritmos em JavaScript
![]()
![]()
Este repositório contém exemplos baseados em JavaScript de muitos algoritmos e estruturas de dados populares.
Cada algoritmo e estrutura de dado possui seu próprio README com explicações relacionadas e links para leitura adicional (incluindo vídeos para YouTube)
Leia isto em outros idiomas: English 简体中文, 繁體中文, 한국어, 日本語, Polski, Français, Español, Русский, Türk, Italiana
Estrutura de Dados
Uma estrutura de dados é uma maneira particular de organizar e armazenar dados em um computador para que ele possa ser acessado e modificado de forma eficiente. Mais precisamente, uma estrutura de dados é uma coleção de dados valores, as relações entre eles e as funções ou operações que podem ser aplicadas a os dados.
B - Iniciante, A - Avançado
BLista Encadeada (Linked List)BLista Duplamente Ligada (Doubly Linked List)BFila (Queue)BStackBTabela de Hash (Hash Table)BHeapBFila de Prioridade (Priority Queue)AÁrvore de prefixos (Trie)AÁrvore (Tree)AÁrvore de Pesquisa Binária (Binary Search Tree)AÁrvore AVL (AVL Tree)AÁrvore Vermelha-Preta (Red-Black Tree)AÁrvore de Segmento (Segment Tree) - com exemplos de consultas min / max / sum rangeAÁrvore Fenwick (Fenwick Tree) (Árvore indexada binária)
AGráfico (Graph) (ambos dirigidos e não direcionados)AConjunto Disjuntor (Disjoint Set)AFiltro Bloom (Bloom Filter)
Algoritmos
Um algoritmo é uma especificação inequívoca de como resolver uma classe de problemas. Isto é um conjunto de regras que define precisamente uma sequência de operações.
B - Iniciante, A - Avançado
Algoritmos por Tópico
- Matemática
BManipulação Bit - set/get/update/clear bits, multiplicação / divisão por dois, tornar negativo etc.BFatorialBNúmero de FibonacciBTeste de Primalidade (método de divisão experimental)BAlgoritmo Euclidiano - calcular o maior divisor comum (GCD)BMínimo múltiplo comum (LCM)BPeneira de Eratóstenes - encontrar todos os números primos até um determinado limiteBPotência de dois - verifique se o número é a potência de dois (algoritmos ingênuos e bit a bit)BTriângulo de PascalBNúmero complexo - números complexos e operações básicas com elesAPartição inteiraAAlgoritmo Liu Hui π - cálculos aproximados de π baseados em N-gons
- Conjuntos
BProduto cartesiano - produto de vários conjuntosBPermutações de Fisher–Yates - permutação aleatória de uma sequência finitaAPotência e Conjunto - todos os subconjuntos de um conjuntoAPermutações (com e sem repetições)ACombinações (com e sem repetições)AMais longa subsequência comum (LCS)AMaior subsequência crescenteASupersequência Comum mais curta (SCS)AProblema da mochila - “0/1” e “Não consolidado”AMáximo Subarray - “Força bruta” e “ Programação Dinâmica” versões (Kadane’s)ASoma de Combinação - encontre todas as combinações que formam uma soma específica
- Cadeia de Caracteres
BHamming Distance - número de posições em que os símbolos são diferentesALevenshtein Distance - distância mínima de edição entre duas sequênciasAKnuth–Morris–Pratt Algorithm (Algoritmo KMP) - pesquisa de substring (correspondência de padrão)AZ Algorithm - pesquisa de substring (correspondência de padrão)ARabin Karp Algorithm - pesquisa de substringALongest Common SubstringARegular Expression Matching
- Buscas
BLinear SearchBJump Search (ou Bloquear pesquisa) - pesquisar na matriz ordenadaBBinary Search - pesquisar na matriz ordenadaBInterpolation Search - pesquisar em matriz classificada uniformemente distribuída
- Classificação
BBubble SortBSelection SortBInsertion SortBHeap SortBMerge SortBQuicksort - implementações local e não localBShellsortBCounting SortBRadix Sort
- Arvóres
BDepth-First Search (DFS)BBreadth-First Search (BFS)
- Gráficos
BDepth-First Search (DFS)BBreadth-First Search (BFS)BKruskal’s Algorithm - encontrando Árvore Mínima de Abrangência (MST) para grafo não direcionado ponderadoADijkstra Algorithm - encontrar caminhos mais curtos para todos os vértices do grafo a partir de um único vérticeABellman-Ford Algorithm - encontrar caminhos mais curtos para todos os vértices do grafo a partir de um único vérticeAFloyd-Warshall Algorithm - encontrar caminhos mais curtos entre todos os pares de vérticesADetect Cycle - para gráficos direcionados e não direcionados (versões baseadas em DFS e Conjunto Disjuntivo)APrim’s Algorithm - encontrando Árvore Mínima de Abrangência (MST) para grafo não direcionado ponderadoATopological Sorting - Métodos DFSAArticulation Points -O algoritmo de Tarjan (baseado em DFS)ABridges - Algoritmo baseado em DFSAEulerian Path and Eulerian Circuit - Algoritmo de Fleury - Visite todas as bordas exatamente uma vezAHamiltonian Cycle - Visite todas as bordas exatamente uma vezAStrongly Connected Components - Algoritmo de Kosaraju’sATravelling Salesman Problem - rota mais curta possível que visita cada cidade e retorna à cidade de origem
- criptografia
BPolynomial Hash - função de hash de rolagem baseada em polinômio
- Sem categoria
BTower of HanoiBSquare Matrix Rotation - algoritmo no localBJump Game - backtracking, programação dinâmica (top-down + bottom-up) e exemplos gananciososBUnique Paths - backtracking, programação dinâmica e exemplos baseados no triângulo de PascalBRain Terraces - trapping problema da água da chuva (programação dinâmica e versões de força bruta)AN-Queens ProblemAKnight’s Tour
Algoritmos por Paradigma
Um paradigma algorítmico é um método ou abordagem genérica subjacente ao design de uma classe de algoritmos. É uma abstração maior do que a noção de um algoritmo, assim como algoritmo é uma abstração maior que um programa de computador.
- Força bruta - look at all the possibilities and selects the best solution
BLinear SearchBRain Terraces - trapping problema da água da chuvaAMaximum SubarrayATravelling Salesman Problem - rota mais curta possível que visita cada cidade e retorna à cidade de origem
- Greedy - choose the best option at the current time, without any consideration for the future
BJump GameAUnbound Knapsack ProblemADijkstra Algorithm - finding shortest path to all graph verticesAPrim’s Algorithm - encontrando Árvore Mínima de Abrangência (MST) para grafo não direcionado ponderadoAKruskal’s Algorithm - encontrando Árvore Mínima de Abrangência (MST) para grafo não direcionado ponderado
- Divide and Conquer - dividir o problema em partes menores e depois resolver essas partes
BBinary SearchBTower of HanoiBPascal’s TriangleBEuclidean Algorithm - calculate the Greatest Common Divisor (GCD)BMerge SortBQuicksortBTree Depth-First Search (DFS)BGraph Depth-First Search (DFS)BJump GameAPermutations (com e sem repetições)ACombinations (com e sem repetições)
- Dynamic Programming - criar uma solução usando sub-soluções encontradas anteriormente
BFibonacci NumberBJump GameBUnique PathsBRain Terraces - trapping problema da água da chuvaALevenshtein Distance - distância mínima de edição entre duas sequênciasALongest Common Subsequence (LCS)ALongest Common SubstringALongest Increasing SubsequenceAShortest Common SupersequenceA0/1 Knapsack ProblemAInteger PartitionAMaximum SubarrayABellman-Ford Algorithm - encontrando o caminho mais curto para todos os vértices do gráficoAFloyd-Warshall Algorithm - encontrar caminhos mais curtos entre todos os pares de vérticesARegular Expression Matching
- Backtracking - da mesma forma que a força bruta, tente gerar todas as soluções possíveis, mas cada vez que você gerar a próxima solução, você testará
se satisfizer todas as condições, e só então continuar gerando soluções subseqüentes. Caso contrário, volte atrás e siga um caminho diferente para encontrar uma solução. Normalmente, a passagem DFS do espaço de estados está sendo usada.
BJump GameBUnique PathsAHamiltonian Cycle - Visite todos os vértices exatamente uma vezAN-Queens ProblemAKnight’s TourACombination Sum - encontre todas as combinações que formam uma soma específica
- Branch & Bound - lembre-se da solução de menor custo encontrada em cada etapa do retrocesso pesquisar e usar o custo da solução de menor custo encontrada até o limite inferior do custo de solução de menor custo para o problema, a fim de descartar soluções parciais com custos maiores que o solução de menor custo encontrada até o momento. Normalmente, a travessia BFS em combinação com a passagem DFS do espaço de estados árvore está sendo usada
Como usar este repositório
Instalar todas as dependências
npm install
Executar o ESLint
Você pode querer executá-lo para verificar a qualidade do código.
npm run lint
Execute todos os testes
npm test
Executar testes por nome
npm test -- 'LinkedList'
Parque infantil
Você pode brincar com estruturas de dados e algoritmos em ./src/playground/playground.js arquivar e escrever
testes para isso em ./src/playground/__test__/playground.test.js.
Em seguida, basta executar o seguinte comando para testar se o código do seu playground funciona conforme o esperado:
npm test -- 'playground'
Informação útil
Referências
▶ Estruturas de dados e algoritmos no YouTube
Notação Big O
Ordem de crescimento dos algoritmos especificados em notação Big O.
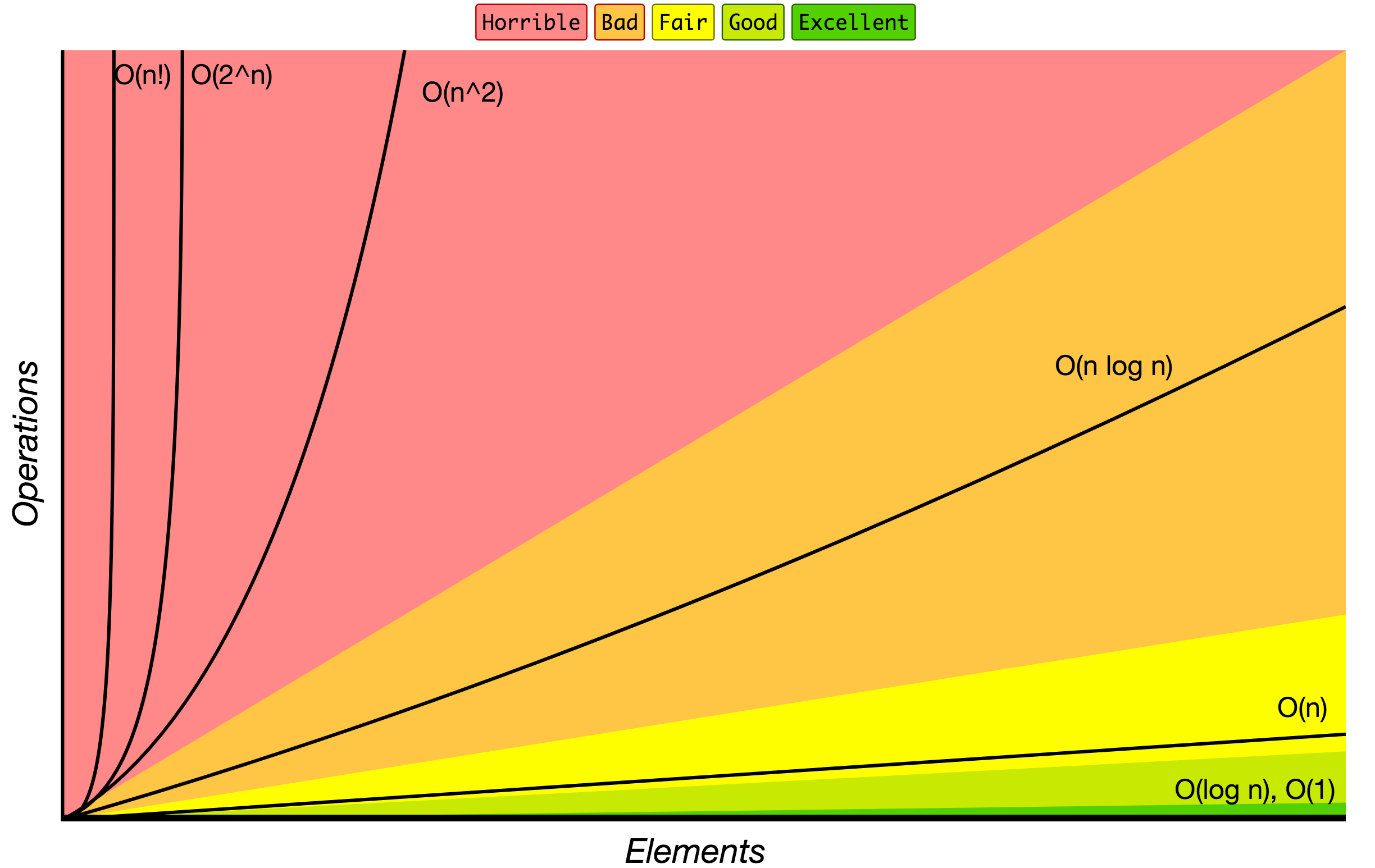
Fonte: Notação Big-O dicas.
Abaixo está a lista de algumas das notações Big O mais usadas e suas comparações de desempenho em relação aos diferentes tamanhos dos dados de entrada.
| Notação Big-O | Cálculos para 10 elementos | Cálculos para 100 elementos | Cálculos para 1000 elementos |
|---|---|---|---|
| O(1) | 1 | 1 | 1 |
| O(log N) | 3 | 6 | 9 |
| O(N) | 10 | 100 | 1000 |
| O(N log N) | 30 | 600 | 9000 |
| O(N^2) | 100 | 10000 | 1000000 |
| O(2^N) | 1024 | 1.26e+29 | 1.07e+301 |
| O(N!) | 3628800 | 9.3e+157 | 4.02e+2567 |
Complexidade de operações de estrutura de dados
| estrutura de dados | Acesso | Busca | Inserção | Eliminação | comentários |
|---|---|---|---|---|---|
| Array | 1 | n | n | n | |
| Stack | n | n | 1 | 1 | |
| Queue | n | n | 1 | 1 | |
| Linked List | n | n | 1 | 1 | |
| Hash Table | - | n | n | n | Em caso de uma função hash perfeita, os custos seriam O (1) |
| Binary Search Tree | n | n | n | n | No caso de custos de árvore equilibrados seria O (log (n)) |
| B-Tree | log(n) | log(n) | log(n) | log(n) | |
| Red-Black Tree | log(n) | log(n) | log(n) | log(n) | |
| AVL Tree | log(n) | log(n) | log(n) | log(n) | |
| Bloom Filter | - | 1 | 1 | - | Falsos positivos são possíveis durante a pesquisa |
Array Sorting Algorithms Complexity
| Nome | Melhor | Média | Pior | Mémoria | Estável | comentários |
|---|---|---|---|---|---|---|
| Bubble sort | n | n2 | n2 | 1 | Sim | |
| Insertion sort | n | n2 | n2 | 1 | Sim | |
| Selection sort | n2 | n2 | n2 | 1 | Não | |
| Heap sort | n log(n) | n log(n) | n log(n) | 1 | Não | |
| Merge sort | n log(n) | n log(n) | n log(n) | n | Sim | |
| Quick sort | n log(n) | n log(n) | n2 | log(n) | Não | O Quicksort geralmente é feito no local com o espaço de pilha O O(log(n)) stack space |
| Shell sort | n log(n) | depende da sequência de lacunas | n (log(n))2 | 1 | Não | |
| Counting sort | n + r | n + r | n + r | n + r | Sim | r - maior número na matriz |
| Radix sort | n * k | n * k | n * k | n + k | Sim | k - comprimento da chave mais longa |